Wordt een taal gemakkelijker wanneer veel mensen haar leren? Daarover woedt al enige tijd discussie in taalkundige kringen. Aan de ene kant hebben mensen een bijna instinctieve afkeer van de gedachte dat je talen überhaupt op een schaal zou kunnen plaatsen van eenvoudig naar complex. Dat idee is in het verleden ook wel misbruikt om racistische gedachten te ondersteunen: simpele talen worden gesproken door simpele mensen. Bovendien is het idee van relatieve eenvoud in tegenspraak met wat we vinden: kinderen over de hele wereld doen er in grote lijnen even snel over om hun moedertaal te leren.
Aan de andere kant is het ook weer niet zo’n gekke gedachte dat een taal op een bepaalde schaal eenvoudiger wordt als buitenstaanders haar leren. Het is óók een ervaringsfeit dat veel naamvallen of ingewikkelde werkwoordvervoeging een taal moeilijker maakt als vreemdeling. Hier zit dus misschien een verschil tussen een taal leren als je moedertaal (L1 heet dat dan) of als vreemde taal (L2). Misschien zijn volwassenen minder goed in het leren van die eigenaardige kronkels die kinderen moeiteloos oppikken. Als er nu in een gemeenschap veel L2-sprekers komen, dan groeien nieuwe generaties L1-sprekers op terwijl ze veel ‘fouten’ horen. Die fouten maken het lastiger om dan het goede systeem alsnog op te pikken – je krijgt teveel tegenstrijdige informatie als kind. Op die manier zouden talen dus in ieder geval in sommige opzichten (zoals vervoeging en verbuiging) wel degelijk eenvoudiger kunnen worden. Verschillen tussen talen liggen dan niet aan de aangeboren intelligentie van de sprekers, maar aan de openheid van de samenleving.
Geavanceerd
Dit is natuurlijk typisch iets wat je zou kunnen meten: neem een aantal talen en zet de relatieve hoeveelheid L2-sprekers af tegen de grammaticale complexiteit. Het probleem is dan alleen dat het aantal L2-sprekers van een taal doorgaans nergens geadministreerd wordt (hoeveel zijn dat er voor het Nederlands?) en trouwens ook dat grammaticale complexiteit op zich al niet zo gemakkelijk in een getal is om te zetten. Alle metingen zijn dus inherent onzeker.
In de discussie is nu een nieuw artikel op internet verschenen dat een in mijn ogen overtuigend antwoord biedt op een recent artikel in het prestigieuze Royal Society Open Science. In dat tijdschrift beweerde Alexander Koplenig dat er geen relatie bestond tussen complexiteit en hoeveelheid L2-leerders. Hij keek daarvoor naar 2000 talen in de grote talendatabase Ethnologue (naar schatting zijn er ongeveer 7000 talen op de wereld), bekeek hoe ingewikkeld de patronen van verbuiging en vervoeging zijn (dat kun je vrij gemakkelijk kwantificeren: hoeveel verschillende vormen zijn er voor een zelfstandig naamwoord of een werkwoord?) en naar de hoeveelheden L2-leerders. En hij vond geen verband.
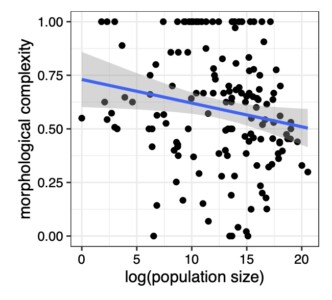
Bron Language structure is influenced by the proportion of non-native speakers: A reply to Koplenig
Dat laatste kwam, zeggen de auteurs van het nieuwe artikel, door een truc die hij toepaste. Omdat in Ethnologue voor heel veel talen niet vermeld staat hoeveel L2-sprekers er zijn, nam hij ook talen in beschouwing waarvan de Ethnologue zegt dat ze vehicular languages zijn, voertalen, wat wil zeggen dat ze ook buiten de oorspronkelijke gemeenschap gesproken werden. Dat maakte de verzameling talen misschien groot genoeg om geavanceerde statistiek op te doen, zeggen de critici, maar feitelijk is die informatie te nietszeggend. Als je talen met die onduidelijke status uit de oorspronkelijke gegevensverzameling haalt, moet je je misschien beperken tot wat minder vergevorderde statistiek – maar dan vindt je wel degelijk een verband tussen hoeveel mensen een taal als vreemde taal leren en de eenvoud van die taal.
Expansie
Beide artikelen zijn het overigens wel eens over een ander verband: hoe groter een taal (dat wil zeggen: hoe meer L1- én L2-sprekers), hoe eenvoudiger de grammatica. Ik denk dat je dit effect aan iets vergelijkbaars kunt toeschrijven. Een taal kan groot worden door expansie, bijvoorbeeld omdat een bepaald gebied op al dan niet vreedzame manier wordt overgenomen en de oorspronkelijke bevolking overstapt. De eerste generaties zijn dan L2-sprekers en kunnen zo hun invloed hebben; als die expansie enkele eeuwen achter ons ligt, hoef je nu niet veel L2-sprekers meer te hebben – de nieuwe generaties zijn helemaal overgestapt – maar het effect kan er toch zijn geweest.
In de tweede plaats heeft een grote taal meestal verschillende dialecten, die hun vervoeging en verbuiging net een beetje anders regelen. De dominante variant van de taal, de standaardtaal, is dan feitelijk voor veel sprekers een soort L2.
Ik denk dat beide factoren een rol hebben gespeeld in de betrekkelijke vereenvoudiging die het Nederlands heeft ondergaan sinds de middeleeuwen: we hebben bijvoorbeeld nauwelijks nog naamvallen, en dat komt door de expansie van de Vlaams-Hollandse standaardtaal naar andere gebieden.
Reacties (7)
Ik moest even aan Rupert Sheldrake denken:
hij opperde de hypothese dat als veel mensen een vaardigheid beheersen, anderen de vaardigheid vanzelf makkelijker aanleren.
Dan moeten Engels en Spaans nu makkelijkere talen geworden zijn.
Het Engels wordt veel geleerd als tweede taal maar ik denk dat dit niet veel invloed heeft op het Engels, want het onderwijs richt zich op een min of meer gestandaardiseerde versie van de taal.
Maar misschien gaat het nog eens veranderen als de EU, Afrika en Azië besluiten zich niets aan te trekken van de gebruiken van taalgebruikers in het VK en de VS.
(zodat “half 4” hier gewoon 15.30 betekent in plaats van 16.30 !)
(Correctie: de Ieren bedoelen ook 16.30 als ze “half four” zeggen, en Ierland is ook in de EU.
Maar misschien kunnen we ze overtuigen om Iers te gaan praten)
Waar naar toe dan? Zuid Afrika? Indonesië? New York? Brazilië? Suriname?
Zuid Afrikaans is een aparte taal geworden en ik kan me slecht voorstellen dat de Indonesische varianten e.d. via (de geschriften van) Nederlandse ambtenaren naar Nederland konden komen.
Ik had eerder eens gelezen dat het Engels zo eenvoudig is omdat het land telkenmale overspoeld werd met andere volken zoals de Vikingen, Romeinen, Bretangers etc.
Voor Het Nederlands zou dat ook wel eens kunnen gelden met die vluchtelingen zoals de Hugenoten, Protestanten, de invasie van de Fransen, de talloze Duitse gastarbeiders, Tjechische dienstmeiden.
Help, de omvolking van onze taal is al begonnen!
:-)
Ik denk dat de andere gebieden Gelderland, overrijssel enz. zijn.
Of het ook in ons wingewest Limburg gelukt is, weet ik niet.
Ook het West-Fries is denk uit Noord-Holland aan het verdwijnen.
“Dat laatste kwam, zeggen de auteurs van het nieuwe artikel, door een truc die hij toepaste.”
Die kun je ook omdraaien, de auteurs hebben een truc toegepast door een aantal willekeurige talen te verwijderen (sterker nog, ze hebben dat op drie verschillende manieren gedaan, met steeds een ander setje talen dat verwijderd werd). Daarnaast is er nog iets aan de hand; Ze hebben geen analyses gedaan met het aantal L2 sprekers, maar eentje met het aantal sprekers (dus L1 en L2 samen) en de proportie L2 sprekers als onafhankelijke variabelen. Dat lijkt misschien ongeveer hetzelfde, maar dat is het helemaal niet. En zelfs dan komt er nog een zwak verband uit (beide variabelen samen verklaren, afhankelijk van de analyse, 11-16% van de complexiteit en elk apart aan de scatterplots te zien nog een stuk minder).