DATA - Jeroen van der Ham is onderzoeker en docent bij de opleiding System and Network Engineering van de Universiteit van Amsterdam. Hij schrijft voor het Rathenau Instituut een serie blogs over ethische vraagstukken bij data-onderzoeken. In deze bijdrage laat hij zien dat het goed anonimiseren van open data geen eenvoudige opgave is.
In 2013 kwam Chris Whong erachter dat de data van alle taxi-ritten in New York City opvraagbaar was via de Amerikaanse variant van een verzoek op de Wet Openbaarheid Bestuur (WOB).
Na het invullen van wat formulieren en een paar dagen wachten ontving hij een USB stick met daarop bijna 20 Gigabyte aan data over de taxi-ritten in New York City in de afgelopen jaren. Elke taxi-rit was beschreven door een regel met daarin onder meer het begin- en eindtijd, vertrekpunt en eindpunt en het aantal passagiers. De prijs en de fooi waren in een apart bestand meegegeven. In de originele data was al deze data gekoppeld aan een taxi. In een poging die identiteit te verhullen, maar toch nuttige data op te leveren was dit versleuteld meegeleverd in de geopenbaarde data.
Chris Whong heeft mooie plaatjes en visualisaties gemaakt met de data die hij kreeg. Populaire plekken waar taxi’s langsrijden, frequentie waarmee taxi’s rijden, de inkomens en fooi verdeling, enzovoort. Hij heeft de data ook beschikbaar gesteld voor anderen, zodat andere “civiele hackers” ermee aan de slag konden.
Al snel was er iemand die de versleutelde identificatienummers van de taxi’s eens beter bekeek. Het viel ineens op dat er een nummer onmogelijk vaak terugkwam. Uiteindelijk bleek dat de versleuteling van het getal “0” te zijn, en zo werd de rest van de getallen vrij makkelijk gebroken door een zogenaamde “regenboog tabel” aan te leggen. De taxi-identificatienummers hebben een vaste structuur en hebben daarom maar vrij weinig mogelijkheden. Met een computer is het vrij simpel om de versleuteling uit te rekenen voor elk van die nummers, en op die manier kan voor elke taxi regel de identificatiecode teruggerekend worden. Zo is vrij snel te zien welke taxi waar actief is geweest, en wat een chauffeur in een jaar verdiend heeft, inclusief fooien.
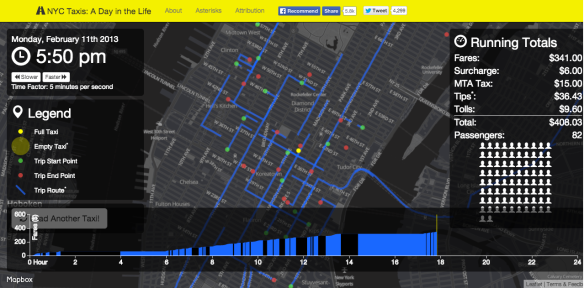
Visualisatie van taxi ritten door Chris Whong (via ChrisWhong.com)
Maar niet alleen de chauffeurs zijn slachtoffer van deze reidentificatie. Later is iemand aan de slag gegaan met foto’s van beroemdheden die in New York waren gesignaleerd terwijl ze in of uit een taxi stapten. Die foto’s zijn weer vrij makkelijk te koppelen aan een tijd, en samen met het nummer dat zichtbaar is op de taxi, kon zo de rit weer teruggevonden worden. En op die manier kon vastgesteld worden dat de ene beroemdheid wat scheutiger met fooien is dan een andere.
Duiding
Bovenstaand geval laat zien dat het niet simpel is om data te anonimiseren. De ambtenaar die het verzoek behandelde dacht met een simpele handeling de identificatie van taxi chauffeurs onmogelijk te maken, maar uiteindelijk bleek dat niet goed genoeg te zijn. In dit geval was er door een combinatie van onhandige versleuteling en teveel structuur in het origineel mogelijk om te deanonimiseren.
De deanonimisatie van data gebeurt niet alleen maar bij taxi-data in New York, maar kan bij allerlei data gebeuren. In Nederland wordt bij medische of statistische data vaak gereduceerd tot bijvoorbeeld de postcode, het geslacht en de geboortedatum, bijvoorbeeld om te kijken naar effecten van blootstelling aan luchtvervuiling in bepaalde gebieden, en of dat anders is voor mannen en voor vrouwen.
Een goede graadmeter voor anonimiteit in een dataset is de zogenaamde k-anonimiteit (Sweeney 2002); gegeven een set kenmerken, tot hoeveel personen kan je dat dan reduceren? Bijvoorbeeld, hoeveel mensen hebben nu precies dezelfde postcode, geslacht en geboortedatum? Het blijkt dat in Nederland een heel groot deel van de mensen uniek identificeerbaar zijn met die kenmerken. En als we het beperken tot de 4 cijfers van de postcode en de geboortedatum, zijn nog steeds tweederde van de Nederlanders nog steeds uniek (Koot 2010).
Conclusie
Anonimiseren van data is dus zo gemakkelijk nog niet. De structuur van de bron dataset, of het onderscheidend vermogen met algemene gegevens moet goed bekeken worden. Er moet een goede afweging gemaakt worden tussen wat er precies nodig is voor het analyseren van die dataset, en wat er wordt vrijgegeven. Deze afweging maken wordt ook steeds moeilijker, omdat er steeds meer verschillende data sets beschikbaar zijn. In Amerika moet je geregistreerd zijn om te mogen stemmen, en die dataset is publiek. Die dataset kan dan weer gebruikt worden om de anonimisatie in een andere dataset heel makkelijk ongedaan te maken (Sweeney 2002). In Nederland is dat iets moeilijker om te herleiden naar een naam, maar het is wel goed te doen om terug te komen tot een uniek persoon. Met wat extra moeite is dan een zo’n persoon vaak weer te heridentificeren.
Het is te overwegen om datasets niet zomaar uit te delen, maar om onderzoekers analysemethoden aan te laten leveren. Of om expliciet afspraken te maken over het vernietigen van de aangeleverde data.
- Koot, M.R., G. van ‘t Noordende & C. de Laat (2010). A study on the re-identifiability of Dutch citizens. In A. Serjantov & C. Troncoso (Eds.), HotPETs 2010 proceedings (pp. 35-49). http://dare.uva.nl/document/2/86818
- L. Sweeney. k-anonymity: a model for protecting privacy. International Journal on Uncertainty, Fuzziness and Knowledge-based Systems, 10 (5), 2002; 557-570. http://dataprivacylab.org/dataprivacy/projects/kanonymity/kanonymity.pdf
Reacties (14)
@0 het probleem is helder, maar gooi je niet het kind met het badwater weg als je een ambtenaar elk informatie verzoek moet gaan laten testen? Ik verwacht dat de informatie dan in een groot aantal gevallen helemaal niet meer verstrekt wordt. Verder kan zo’n check ook weer tot een schijnveiligheid leiden, bijvoorbeeld als het resultaat van twee verschillende onderzoeken te combineren valt tot privacy gevoelige informatie. Zoals het celebrity onderzoek wat je schetst. Dat verhelp je niet per se.
Ik vindt het taxivoorbeeld eerder iets anders schetsen. Die ambtenaar had onvoldoende kennis van zaken. Volgens mij kan je als organisatie beter investeren in kennis over privacy, door een specialist aan te nemen zoals Jeroen van der Ham. En die persoon verantwoordelijkheid te geven voor het gehele informatiemanagement van een overheid. Net als een jurist verantwoordelijk is voor de juridische houdbaarheid van maatregelen.
@0: “te overwegen om datasets niet zomaar uit te delen”
Wat een zwaktebod van deze onderzoeker.
Ontwerp een gemakkelijke, betere methode voor anonimisering.
@3, ja, doe dat even!
Het punt in het artikel is juist dat het niet zo eenvoudig is om een goede methode voor anonimisering te ontwerpen. (En dat geldt dus zelfs als je cryptografisch sterke hashes gebruikt, of volkomen willekeurige guids.) De data zelf bevat namelijk de informatie om iemands identiteit met redelijke zekerheid te kunnen herleiden. Het ‘anonimiseren’ kan dan op geen enkele andere manier dan werkelijk minder informatie aan te leveren – met alle gevolgen voor de nauwkeurigheid voor de conclusies van dien. En da’s natuurlijk wel relevant als het gaat om medisch onderzoek.
(Zo zijn de 4 cijfers van de postcode niet voldoende om bv vast te stellen of iemand wel of niet langs een drukke weg woont, maar kun je op basis van volledige postcode en geboortejaar en geslacht nog wel behoorlijk precies bepalen om wie het gaat. En da’s bij astma misschien minder erg dan bij conclusies over seksueel misbruik…)
Als je dat dilemma hebt opgelost op een gemakkelijke en betere manier, dan moet je dat vooral even laten weten, ik denk dat men erg geinteresseerd is.
@4: Wat dat artikel vooral laat zien is dat je niet moet denken dat je geanonimizeerde microdata openbaar kunt maken. Maar het is prima werkbaar om geanonimizeerde data aan onderzoekers te geven en te vertrouwen op de ethiek van onderzoekers (in combinatie met een contractje waarin staat dat ‘gij niet op zoek zult gaan naar individuen met de bedoeling die informatie te publiceren’).
Je kunt wel met onthullings- en geheimhoudingsregels gaan werken (‘voor iedere combinatie van variabelen moeten minimaal 10 individuen aanwezig zijn’), maar d’r zijn domweg teveel variabelen aanwezig. En in geval van sleutels als sofinummers of NAW-gegevens die over alle bestanden gelijk zijn: er zijn teveel bestanden met achtergrondkenmerken die je er ook nog eens aan zou kunnen koppelen.
Dus het ligt wat genuanceerder dan @0 stelt: je moet microdata niet ‘out in the open’ gooien, maar wel ter beschikking stellen aan onderzoekers, en ze ook aanspreken op hun gedrag als ze moedwillig individuele cases er uit lichten.
Vertrouwen op integriteit doe ik liever niet zolang integriteit niet echt als belangrijke waarde gezien wordt. (Via Blendle: https://blendle.nl/i/de-groene-amsterdammer/ondernemende-professoren/bnl-groeneamsterdammer-20141126-1_20_1 Hoewel dat over iets anders gaat, geeft het vooral aan dat integriteit niet iets is dat heel erg doorleefd wordt – iedereen neemt maar zo’n beetje aan dat een wetenschapper dat automatisch heeft. Zelfs al is er niet echt een reden om dat aan te nemen.)
Hoe fijnmazig moet data zijn om microdata te zijn? En hoe grof kun je je data maken om nog iets zinnigs te zeggen over de dataset? Het punt is immers dat bij de taxi-data het de data zelf is die zowel nuttig als identificerend is. Je zou alleen start- en eindpunten kunnen registreren en uberhaupt niet een verbinding met taxi’s maken (dus niet kunnen zeggen of een bepaalde taxi zowel ritje x als y heeft gemaakt), maar dan kun je bv ook geen conclusies trekken over werkdruk / inkomen van taxichauffeurs in het algemeen, omdat je bv niet weet hoe goed de ritten op elkaar aansluiten.
@4: Als je kijkt naar de fout die gemaakt is: er zijn MD5 checksums gebruikt als hash. Dat is dus duidelijk gedaan door iemand die wel eens heeft gehoord van privacy en versleuteling, maar er niet echt verstand van heeft. Zie: https://medium.com/@vijayp/of-taxis-and-rainbows-f6bc289679a1
Ik denk dat Gronk een deel van de oplossing aandraagt. Iets wat nu eigenlijk al voor een deel gebeurt. Je begeeft je als overheid of onderzoeker op juridisch glad ijs als je privacygevoelige informatie openbaar aanbiedt. Als iemand je wil vervolgen tenminste.
Maar dan blijft dat overheden en bedrijven vaak databases beheren en daarbij onvoldoende kennis en besef hebben van zowel privacy als beveiliging. Daarom denk ik dat je ook iemand vast in dienst moet hebben bij bedrijven en overheden die zich daarmee bezig houden die technisch en juridisch doorhebben wat kan en mag.
@inca: dat is een beetje hetzelfde soort redenatie als destijds met die brabantse schoonmaker die geen allochtonen in dienst wilde nemen:’ik neem geen allochtonen aan want er zijn allochtonen waar een luchtje aan hangt’. Daar kwam-ie niet mee weg. Ik zie niet in waarom je geen data zou mogen delen met onderzoekers ‘omdat er onderzoekers zijn die minder integer zijn’.
Als je onderzoekers toestaat op microdata te laten werken, dan doe je dat in vertrouwen. Als dat vertrouwen beschaamd wordt, dan hoort daar een stevige straf op te staan: juridische stappen, boetes en uitsluiting. Als dat voldoende bekend is dan zullen de niet-integere onderzoekers afhaken.
Het enige waar je weinig aan kunt doen zijn onthullingen van datasets die geaggegeerd leken te zijn maar die in combinatie met extra data toch meer ID’s prijsgeven dan de onderzoekers in eerste instantie hadden gedacht.
Maar ook daarvoor geldt: dan moet je dus actief op zoek gaan om data te gaan de-anonymizeren. En de ethische manier om zoiets te doen is -nadat je dat hebt gevonden- dat te melden bij de onderzoekers, zodat ze stilletjes de data van het net af kunnen halen, als dat nog mogelijk is. Net zoals dat met exploits ook gebeurt.
Je kunt er natuurlijk ook voor kiezen om dat meteen aan de grote klok te hangen, terwijl je ‘sgande, sgande!’ roept. Maar dan IMO ben je dan veel onethischer en immoreler bezig dan de oorspronkelijke onderzoekers, en meer bezig om je eigen standpunt door te drammen (danwel eigengeilerij).
Het is niet voor niets dat ook met security exploits het als ‘ethisch correct’ wordt gezien om dat eerst te melden, en niet meteen met een zero-day-exploit publiek naar buiten te gaan.
@7, het gebruik van checksums is inderdaad onvoldoende, maar zoals ik al zei, en zoals het artikel ook al aangeeft, wordt het probleem niet meteen opgelost, zelfs niet met volkomen random identificaties. Dit omdat er andere manieren zijn om links te leggen (bv foto’s met taxinummers.) Geen cryptografie die je daartegen kan beschermen – wil je dat onmogelijk maken dan moet je de data zelf beperken: bv niet meer exact de tijden of locaties opslaan, en uberhaupt geen taxinummer (ook niet geanonimiseerd) gebruiken. Dan kan er op basis van 1 foto tenminste niet meer gelinkt worden aan andere ritten.
MAAR dan verlies je dus wel aan mogelijkheden wat je met de data kunt doen – je kunt dan bv niet meer zien hoeveel ritjes een taxichauffeur heeft, hoeveel tijd ertussen zit etc.
Dat probleem is fundamenteel: de data zelf bevat genoeg informatie om identificeerbaar te zijn. Gewoon, omdat het fijngevoelige data is. Dat los je niet op met cryptografie.
@8, je leest dingen die er niet staan. Ik zei niet dat wetenschappers automatisch geen data meer mogen ontvangen omdat ze niet integer zijn, maar dat het dom is op integriteit te vertrouwen als je weet dat er weinig waarborgen zijn voor die integriteit. Da’s behoorlijk fundamenteel anders.
Het verschil zeg maar tussen allochtonen niet aan willen nemen omdat ze niet eerlijk (of wat dan ook) zouden zijn, of je magazijn wagenwijd open zetten omdat iedereen vast wel eerlijk is.
Dat tweede is gewoon vrij dom als je waardevolle dingen in dat magazijn hebt.
Verder ga je niet in op wat microdata precies is en welke fijnmazigheid data wel of niet moet hebben. Terwijl dat toch een vrij fundamentele vraag is.
@9: als je al geen voorstelling hebt van ‘microdata’, dan moet je misschien wat minder hoog van de toren blazen. Want dan ben je domweg onvoldoende bekend in ’t vakgebied. Sim-pel.
“Bijvoorbeeld, hoeveel mensen hebben nu precies dezelfde postcode, geslacht en geboortedatum? Het blijkt dat in Nederland een heel groot deel van de mensen uniek identificeerbaar zijn met die kenmerken.”
Een tijdje terug werkte ‘Sargasso’ mee aan een onderzoek, waarbij de gegevens tot op postcodeniveau door (ik meen) het UWV beschikbaar was gesteld.
Wat is er eigenlijk met die berg aan data gebeurd? In hoeverre was die data ‘veilig en anoniem’? En in hoeverre konden de opgeroepen vrijwilligers daar evt. mee aan de haal. En heeft iemand een nog backup voor me (geintje).
@11: dat sentiment is dus precies waar ik me aan stoor. D’r is altijd wel een stuurman aan wal die ‘sgande’ roept omdat er mensen zijn die iets met data doen.
Ondertussen verzamelt de overheid (maar ook bedrijven) steeds meer en meer data, zonder dat je daar veel tegen kunt doen. Naast de oorspronkelijke functie van die data wordt die data vooral gebruikt voor repressie, zoals de eeuwige ‘fraudebestrijding’ en ‘anti-terrorisme-acties’. Met als gevolg dat d’r in nederland een paar duizend MBO’ers (want politieagent) in systeempjes kunnen kijken om na te gaan met wie hun vrouw heeft gebeld, of of die marktplaatsverkoper wel kosher is. De rest van nederland heeft het nakijken.
Dan vind ik dat onderzoekers die met een FOIA-request data opvragen en daar wat mooie visualisaties uit slepen (plus aardige achtergrondinfo over de gemiddelde ritlengte e.d.) veruit te preferereren. Wat die data is onze data, niet data van een of andere opsporingsdienst of commercieel bedrijf.
(Weg, ik ga eerst even beter lezen.)
@12
Jij stoort je wel aan meer/ vaker aan dingen, onterecht.
Neem een voorbeeld aan @13 , voor je verder gaat met bazelen…
Ik leverde geen kritiek en ik schreeuwde geen ‘sgande’. Ik stelde een paar vragen a.d.h.v. een concreet voorbeeld die direct betrekking hebben tot het artikel en het anonimiseren van data – al dan niet in bulk.
Ga nu maar fijn op twitter of andere social media spelen. Kan je de overheid of bedrijven nog een beetje meer data aanleveren..