ONDERZOEK - Datavisualisaties zijn een uitdaging voor de kijker en de maker, betogen Daniela van Geenen en Maurits van der Goes van de Utrecht Data School. Ze deden voor het Rathenau Instituut onderzoek naar de manier waarop algoritmes en keuzes bij het verzamelen, analyseren en visualiseren van gegevens bepalen welk verhaal een dataset vertelt.
We vertrouwen blind op datavisualisaties. De productie van datavisualisaties gebeurt immers automatisch door software. Met de uitvinding van de fotografie bijna 200 jaar geleden ontstond het idee van een geautomatiseerde beeldproductie en de droom van een objectieve afbeelding van de werkelijkheid door technologie. Het maken van een foto biedt de mogelijkheid om een onderwerp visueel vast te leggen. Toch kan er hierbij eigenlijk geen sprake zijn van een objectieve afbeelding. De camera vangt slechts een fractie van het beeld, waarbij dit proces onderhevig is aan vervalsing door onder meer de belichting.
Het gebruik van software heeft de mogelijkheden om een afbeelding te manipuleren verveelvoudigd. Met datavisualisaties wordt op een andere manier gepoogd de werkelijkheid af te beelden: verbanden in data worden zichtbaar gemaakt. Zo is het mogelijk om bijvoorbeeld sociale medianetwerken te visualiseren.
Terwijl we inmiddels kritisch zijn over de echtheid van foto’s, stellen we geen kritische vragen bij datavisualisaties. Maken datavisualisaties de droom van objectiviteit dan waar? Of laten we ons verleiden door de schone schijn van automatisering? Ook datavisualisaties zijn geen objectieve afbeeldingen van de werkelijkheid, maar doordat de meeste van ons de automatische productie hiervan als een ondoorgrondelijke black box ervaren, is het moeilijk om kritische vragen te stellen. We zullen laten zien waarom het zo verleidelijk is om in datavisualisaties te vertrouwen, welke rol de maker hierin speelt en wat we als kijker kunnen doen om ons niet te laten verblinden door hun schone schijn.
Datavisualisaties van netwerken lijken net abstracte kunstwerken met de vloeiende lijnen die verschillende actoren aan elkaar verbinden. Mediatheoretici Frank Kessler en Mirko Tobias Schäfer refereren naar deze visualisaties als ’techno-images’ die overtuigen door hun verleidelijke esthetiek. Wat achter deze schone schijn verborgen blijft, is dat de software die gebruikt wordt om data te visualiseren door mensen is geprogrammeerd. Mensen en hun subjectieve keuzes, evenals software en de specifieke functionaliteit van de algoritmen, spelen een actieve rol in het vormgeven en visueel manipuleren van de data.
Wetenschapshistorici Lorraine Daston en Peter Galison observeren een veranderende beeldcultuur: visualisaties worden als instrumenten gebruikt om eigenschappen van data in een compacte vorm te presenteren en daarmee een gewenst argument uit te drukken. Matthew Norton Wise, ook wetenschapshistoricus, merkt in deze context op: to make things visible is to make them real. Hoewel er, zoals we zullen laten zien, niet enkel één manier of werkelijkheid bestaat bij het visualiseren van dezelfde data.
Mensen zijn getraind in het herkennen en begrijpen van visuele patronen, wat visualisaties heel geschikt maakt om een boodschap over te dragen. Het is daarom de hoogste tijd ons af te vragen wat een verantwoorde omgang met datavisualisaties moet inhouden. Zoals datajournalist John Burn-Murdoch’s in zijn artikel met de provocerende titel Why you should never trust a data visualisation stelt, is een verantwoorde omgang met datavisualisaties tweeledig: verantwoordelijkheid ligt zowel bij de personen die visualisaties maken als bij de kijker. Makers zijn gevraagd om hun keuzes in het analyse- en visualisatieproces inzichtelijk te maken, terwijl de kijker toegang kan krijgen tot de visualisaties door het ontwikkelen van een kijkstrategie.
Een kritische kijkstrategie
Datavisualisaties zijn veelal de resultaten van data-onderzoek, zo ook in het data-onderzoek dat we vorig jaar in het kader van de Utrecht Data School hebben uitgevoerd. In opdracht van het Rathenau Instituut hebben we een netwerk van bestuurders en commissarissen van belangrijke Nederlandse organisaties in kaart gebracht. Dit diende als casestudy om het proces van data-onderzoek kritisch te doorlopen. Onderstaande visualisaties (klik op de afbeeldingen voor grotere versies) zijn geconstrueerd op basis van de dataset die we voor deze casestudy hebben samengesteld:
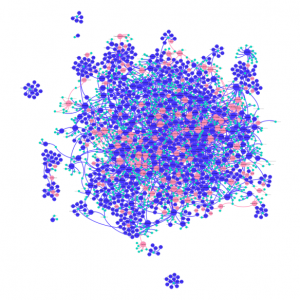
Figuur 1: Het old boys-network van Nederlandse bestuurders en commissarissen gevisualiseerd in Gephi, met gebruik van layout-algoritme Force Atlas 2; kleuren van knopen benadrukken het geslacht van personen (rood: vrouwen, blauw: mannen, groen: organisaties)

Figuur 2: De clustering van Nederlandse bestuurders en commissarissen rondom verschillende organisaties in beeld gebracht met Gephi, hetzelfde layout-algoritme als voor Figuur 1 met de toepassing van LinLog-Mode; kleuren zijn gegenereerd op basis van de statistische functie Modularity Class.
Beide visualisaties kunnen worden beschouwd als onderzoeksresultaten. Belangrijk is echter dat beide visualisaties twee verschillende werkelijkheden presenteren, terwijl ze gebaseerd zijn op dezelfde dataset en zelfs geconstrueerd zijn door de toepassing van hetzelfde layoutalgoritme Force Atlas 2 in visualisatiesoftware Gephi.
Visuele verschillen zijn gebaseerd op de aanpassing van enkele instellingen zoals het zogenaamde behavior alternative LinLog-Mode en de keuze voor het zichtbaar maken van verschillende metadata zoals geslacht van personen. Op deze manier benadrukt figuur 1 een nauw verweven netwerk van vooral mannelijke bestuurders en commissarissen (in het blauw) – het Nederlandse old boys network. Figuur 2 daarentegen laat een veel sterker geclusterd netwerk van verschillende personen zien die duidelijk – door de toepassing van kleur – verbonden zijn aan enkele organisaties.
Hoe kunnen we als kijker dergelijke visualisaties kritisch benaderen? We kunnen de volgende vragen stellen: Wat zie ik hier eigenlijk? Wat betekenen bijvoorbeeld gebruikte kleuren of het verschil in knopengrootte? Welke contextinformatie wordt verstrekt? Kom ik te weten hoe de visualisatie geconstrueerd is: welke software of algoritmen zijn gebruikt? Wat is de bron en heb ik toegang tot de brondata? Kan ik erachter komen hoe de data in het onderzoeksproces ver- en bewerkt zijn?
Op deze manier nemen we als kijker belangrijke stappen om mediageletterdheid te ontwikkelen: het begrip dat software een actieve instantie is, zoals Kessler en Schäfer benadrukken, die data niet alleen vertaalt naar een compacte vorm maar ook interpreteert.
De black box ontsluiten
Op welke manier kunnen makers en media die datavisualisaties publiceren helpen de black box te ontsluiten? Een korte vermelding van de bron, het liefst met een link naar de digitale dataset, is een onmisbaar aspect van de toelichting. Dit geeft de kijker een mogelijkheid de presentatie te toetsen op betrouwbaarheid. De term data lijkt te suggereren dat het gaat om ruwe, onaangetaste gegevens. Van raw data kan echter geen sprake zijn, zoals informaticus Geoffrey C. Bowker met de veel geciteerde zin Raw data is both an oxymoron and a bad idea benadrukte.
Het is namelijk nodig dat deze gegevens in een vorm gegoten, gerangschikt, gefilterd en geclassificeerd worden. Over het algemeen gebeurt dit in tabellarische vorm, wat een visualisatiesoftware zoals Gephi vereist. Met deze verwerking wordt de data aangepast, delen weggelaten en andere aspecten verrijkt met meta-informatie, vaak afkomstig van extra bronnen. Dit is geoorloofd en vaak nodig als voorbereiding voor een heldere visualisatie. Deze keuzes moeten echter wel inzichtelijk gemaakt worden, gezien elke keuze invloed heeft op de resultaten, de visualisaties.
Naast deze claim voor transparantie, willen we pleiten voor visualisaties die zo veel mogelijk recht doen aan de data. Dit betekent dat gemaakte keuzes moeten zorgen voor leesbaarheid en herkenbaarheid. Visualisatie-analist Robert Kosara beschrijft het op de volgende manier:
Pragmatic visualization is what we term the technical application of visualization techniques to analyze data. The goal of pragmatic visualization is to explore, analyze, or present information in a way that allows the user to thoroughly understand the data.
Pragmatische keuzes komen wederom het beste tot hun recht in combinatie met contextinformatie. Hiervoor zijn een korte beschrijving en een legenda noodzakelijk die informatie geven over welke software en instellingen gebruikt zijn. Of onze keuzes die geleid hebben tot bovenstaande visualisaties pragmatische keuzes genoemd mogen worden, is nog maar zeer de vraag. Door de contextinformatie die we geven en de mogelijkheid om in te zoomen op details heeft de kijker echter de mogelijkheid om hierover zelf te oordelen.
Deze transparantie bevordert media- of datageletterdheid: de kijker wordt in staat gesteld om zich ervan bewust te worden dat het vormgevingsproces van een visualisatie bepaald wordt door verschillende actieve instanties: subjectieve keuzes van de maker en algoritmische interpretaties van de software. Datavisualisaties worden op deze manier niet objectiever maar wel toegankelijker voor de kijker, reproduceerbaar en daardoor betrouwbaarder als onderzoeksresultaten.
Daniela van Geenen en Maurits van der Goes zijn masterstudenten aan respectievelijk de Universiteit Utrecht (New Media & Digital Culture) en de TU Delft (SEPAM) en namen deel aan de Utrecht Data School.
Via Data Denkers
Reacties (2)
Dat ik het nog eens eens zou zijn met het Rathenau ;)
Dit lijkt me totale onzin. In de meeste datavisualisaties zit een hoop handwerk.